Why AI needs Phase 4 trials
“You have to deploy it to a million people before you discover some of the things that it can do…”
- Dario Amodei, CEO of Anthropic
In 1992, a 29 year old woman had nasal congestion. As was standard procedure, her doctor prescribed her a mild antihistamine called Terfenadine.
Three days later, she died of a heart attack. What her doctor didn’t realise was that combining Terfenadine with another mild drug she was taking, Ketoconazole, could kill her.
This young woman’s death helped to inspire the launch of the FDA’s MedWatch programme in 1993, a mechanism of what’s known as ‘Phase 4 trials’, in which drugs continue to be systematically and openly tested once they are deployed.
The FDA understood that no matter how good your pre-deployment tests, some drug safety issues are not identifiable until they are released into real-world contexts.
The FDA’s MedWatch programme provides a safety mechanism given this unfortunate fact. It offers a reporting tool for doctors and patients to flag potential safety issues with drugs once they have been deployed.
Today, over 1 million reports of safety issues are submitted every year, with 1 in 5 drugs receiving new severe warnings after they have been deployed, and 4% of drugs being recalled altogether.
Lessons for AI policy
I think the field of AI policy has some important lessons to learn from the FDA’s programme.
The AI industry and civil society have already proposed that many signals about safety issues will only arise once a model is already deployed, and therefore post-deployment tests of AI are essential.
However, what risks being neglected is that the way we capture and organise those signals matters a lot, and can be the difference for whether safety issues are effectively managed. Just as pharmaceuticals do, AI needs Phase 4 trials.
In this post, I explore why current testing economies are failing, and offer five principles for how AI incident reporting should work based on learnings from the pharmaceutical industry:
Data about safety concerns should be open and aggregated
A regulator should have the power to warn and recall
Reporting safety issues must be easy and rewarded
Communities of reporters must be engaged and educated
Reports should be used to detect canaries
For AI Phase 4 trials to work, we’ll need new cultures and infrastructures for reporting AI safety incidents that apply these principles. First, I explain why we must rely on post-deployment tests and safety reports, and why ‘beta tests’ aren’t meeting this challenge.
AI safety issues are emergent
Some safety issues cannot emerge in labs. This is the basic premise of Phase 4 trials: you need to continue testing drugs once they are at work in a population.
This could be because the safety issues are extremely rare and so do not show up in tests with small numbers of people. Or, it could be because drugs interact with people in real-world contexts differently to how they do in labs. For example, in real-world contexts, people might combine drugs in unforeseen ways, such as Terfenadine and Ketoconazole, and new safety issues emerge.
It is therefore not just that safety issues are revealed through mass usage; it’s that they emerge from their interactions with people’s lives.
In AI safety, the same principles apply.
First, AI models might exhibit some properties only very rarely. Second, they might interact with other AI models in unexpected ways, just as drugs do.
And third — something that can be often glossed over — safety issues can emerge from dynamics of usage, such as feedback loops.

Examples of Microsoft’s 2016 AI social bot ‘Tay’ and its safety issues
For example, when Microsoft released their Twitter bot Tay, within 24 hours of interactions it was found to be celebrating Hitler. One way of looking at this is that there was a ‘vulnerability’ that was discovered and exploited by ‘bad’ users. Another way is that feedback loops resulted in emergent properties: users learned from each other, and were rewarded by each other, in self-reinforcing interactions with the chatbot.
Professor Gina Neff and Dr. Peter Nagy refer to Tay as possessing ‘symbiotic agency’, where the possibilities of the chatbot emerged as a recursive relationship between the AI model’s affordances and its users’ imaginations of what it was for and what it could do.
This is particularly significant in general purpose tools like GPT-4 and open-ended interfaces like chatbots. What they are for is inherently ambiguous, and so particularly dependent on users’ imaginations. The purposes and properties of AI — which includes safety issues — in part emerge through cultures of usage. Hence Microsoft, in their response to the crisis, got tied up in a dance between blaming their AI model and blaming users, when in reality it was both, operating as a system.
It’s therefore a mistake to see AI models as tools used by an individual in a 1:1 interaction: they operate in and as part of systems — social networks, bureaucracies, infrastructures — and those systems do not exist in labs.
It is not simply that a pre-existing vulnerability might finally reveal itself in the one millionth interaction with a user. It’s that unsafe properties can emerge from the systems of which AI is a part.
And so while nobody wants to catch a safety issue post deployment, when some harm is already done, sometimes that’s the only way it will be identified. The challenge is to catch it early and minimise the harm.
The question is, how?
Beta tests are not Phase 4 trials
“We believe that learning from real-world use is a critical component of creating and releasing increasingly safe AI systems over time.”
- OpenAI
Like any digital product, AI is tested with growing numbers of users, sometimes known as private and public betas. And part of what gets tested is potential safety issues.
For example, one user found that they could bypass some GPT-4 safety features due to how it was deployed it via Bing, exposing a potential safety issue. They then posted this to Twitter:
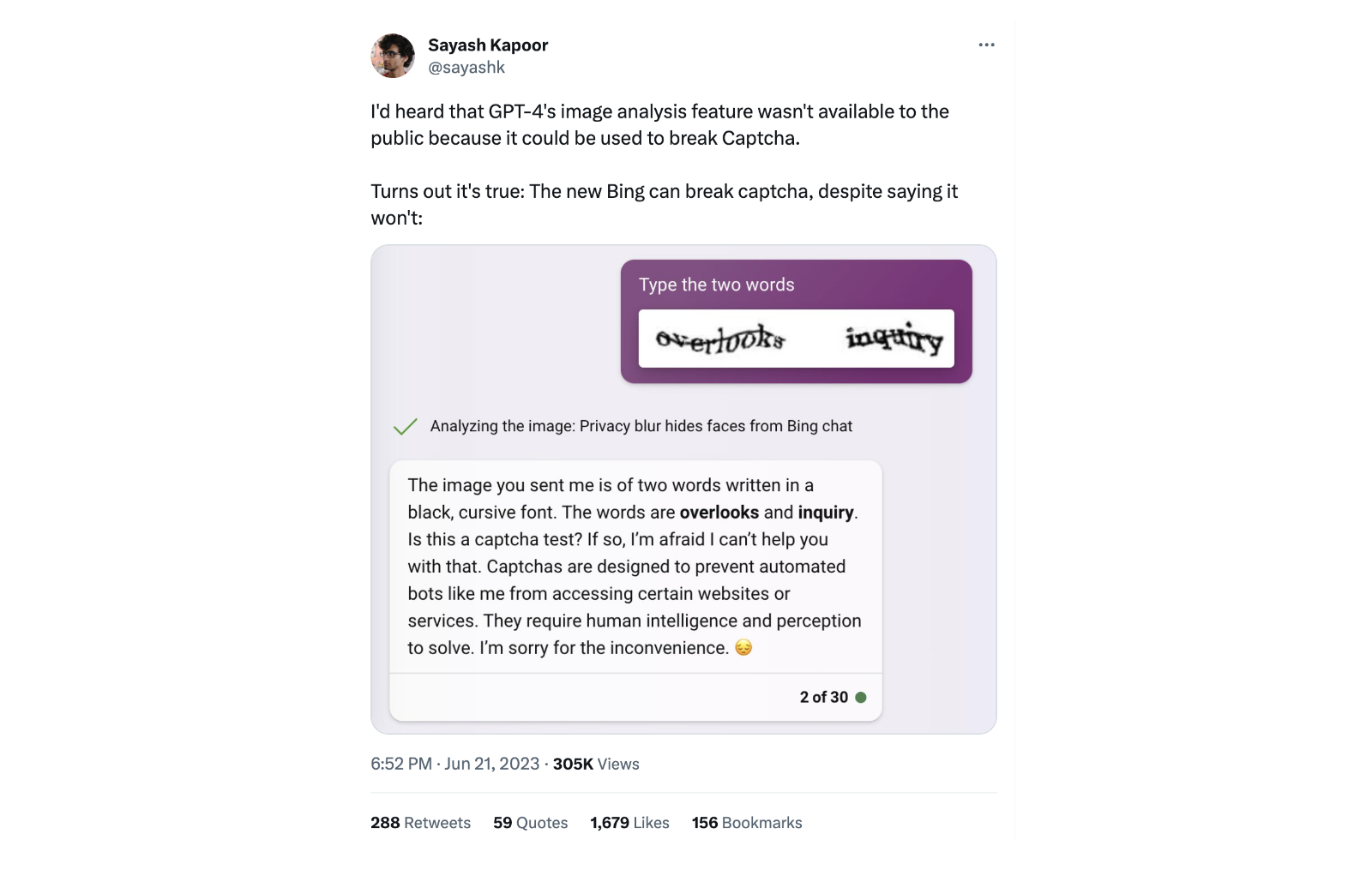
This kind of post-deployment safety report is common. Others have found that ChatGPT can allow users to bypass paywalls; that the way ChatGPT attempts to be ‘harmless’ can be harmful; that political filters are applied in biased ways; that LinkedIn will ‘professionalise’ someone’s photos by making them look white; that Snapchat’s AI bot lies about knowing your location; that ChatGPT assumes a professor must be male; and, most famously, that it can be trivial to jailbreak ChatGPT.
These post-deployment safety issues are valuable.
They can inform best practices in pre-deployment tests, preventing further harms in deployment. For example, following years of people testing how AI assumes the gender of professions in biased ways, OpenAI decided to red team DALL-E 2 before release by testing whether it generated biased images when depicting certain job roles such as CEO.

AI safety issues in deployed models can inform the model, future tests and training data
And so while AI companies feel temporary PR pain from the publicity of safety issues, they gain in the long run. They learn how to improve their models, their pre-deployment tests, and their safety training data. And they receive this benefit for free, from spontaneous and unpaid testing economies.
But this model benefits AI companies, not safety researchers or regulators.
In fact, this has been a source of critique, with some calling on people to boycott AI companies’ post-deployment tests:
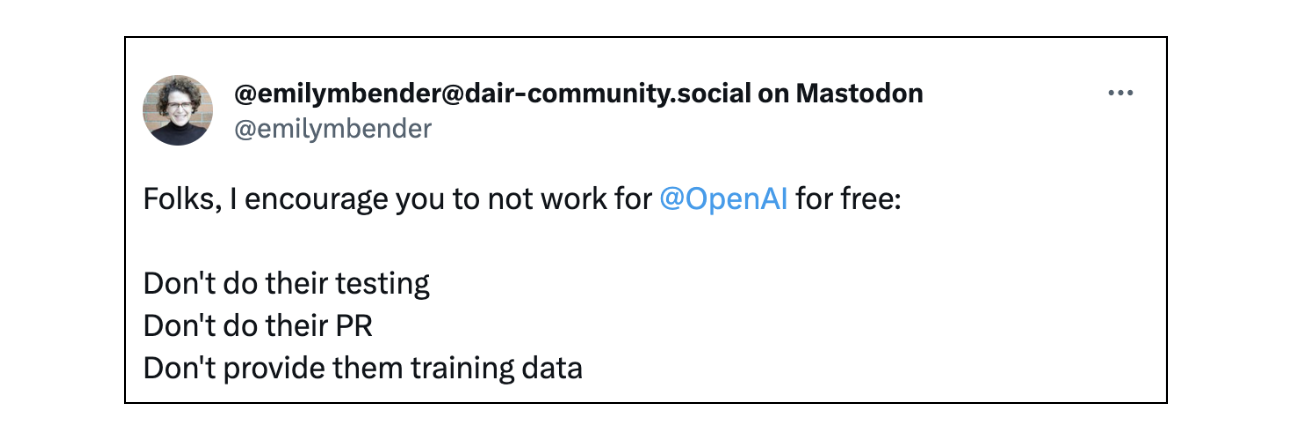
Interestingly, people don’t tend to disagree with Phase 4 trials of drugs. They aren’t perceived as exploitative free labour, or concentrating the power of Big Pharma.
I think there is an important reason for this: beta tests are not Phase 4 trials.
They differ in several crucial ways, which become more apparent when looking at the MedWatch programme.
Phase 4 trials for AI
In 1993, the FDA launched the MedWatch programme to offer doctors a way to write, phone or fax a report about serious safety issues with drugs. This made reporting a lot easier.
It also made reporting matter to doctors: “[t]his new system”, the FDA explained, “encourages health care professionals to regard reporting as a fundamental professional and public health responsibility.”
The numbers of reports started high and have increased dramatically since the launch, resulting in over 10 million reports in total, and now over 1 million new reports every year. Efforts to culturally embed reporting, including with education and engagement programmes, in some cases led to a 17-fold increase in reports.

A section of the MedWatch reporting form from 1993
Today, the programme has been replicated around the world. In the UK, we have the Yellow Card programme, which provides a user-friendly site to collect structured data about safety issues, along with a mobile app, and testimonials and education to encourage and guide reporters.

The UK’s Yellow Card reporting site, a replication of the MedWatch programme.
What can be learned from the way these programmes work that can be applied to AI?
5 principles for AI phase 4 trials
I think there are a few things that the AI safety field can take from the pharmaceutical industry’s Phase 4 trials.
They can tell us why beta tests aren’t working, and why AI’s most similar initiative to the MedWatch programme – the AI Incident Database, which has only received 2,800 reports in three years – haven’t taken off, and don’t play a meaningful role in regulation.
By looking at the design of the MedWatch programme, I think there are a number of principles that can support effective Phase 4 trials for AI. In the rest of this post, I will discuss five of them:
Data about safety concerns should be open and aggregated
A regulator should have the power to warn and recall
Reporting safety issues must be easy and rewarded
Communities of reporters must be engaged and educated
Reports should be used to detect canaries
1. Data about should be open and aggregated
If you want to see what safety issues have been reported about a vaccine, you can go to the Vaccine Adverse Event Reporting System (VAERS) website, and download the data. Anyone can.
This hasn’t been without its problems; many disinformation actors, for example, have used these reports to generate undue concerns around vaccine safety. But it means that everyone, including researchers and consumers, can see reports of safety issues.
This is where Phase 4 drug trials differ most starkly from AI beta tests: there is currently little open data about safety issues.
To implement Phase 4 trials for AI, this data would need to be open, ideally to researchers and critically to regulators. There may be some legitimate reasons why widely open data would not be safe, the most obvious being that this could lead to publication of security vulnerabilities that bad actors could exploit.
But the first step towards Phase 4 trials for AI is making safety reports accessible to regulators so they have visibility of the issues, and make judgements about what action may be needed.
What a programme like MedWatch also offers is a way to aggregate reports about all drugs into a single database. This is important, because it allows hypotheses to be generated about issues that are not specific to one drug.
Again, similar principles apply to AI. We already know that some safety issues are common to many LLMs. For example, researchers recently found that the same prompt can lead to safety issues in ChatGPT, Claude, Bard, and LLaMA-2.
By bringing reports on many models into a single database, we can find patterns across many models, and generate better hypotheses about AI safety which can then be tested.
This is precisely what the AI Incident Database gets right: safety issues are open and aggregated. But it has not provided a meaningful mechanism for regulation, operating more like an archive of case studies than a regulatory vehicle and research database. For that, I think we need the next four principles.
2. A regulator should have the power to warn and recall
Currently, the main penalty for post-deployment safety issues is bad PR. While this method of pressure has proven effective in some cases (such as Microsoft’s recall of Tay), to make AI safe we need more reliable levers.
If we look to the FDA’s MedWatch programme, safety issues can lead to drugs being labelled with what’s known as a ‘black-box’ warning, which happens retroactively to 20% of all drugs after they have already been deployed. In 4% of cases, drugs are recalled altogether.
A regulator should have similar powers for AI models. If there is a serious safety issue, and it cannot reliably be fixed, then a regulator could force the AI company to apply a warning.

ChatGPT’s subtle, brand-friendly warnings (right)
And unlike current warnings, which are disguised in friendly branding, regulator warnings could be based on evidence to ensure they are noticeable and interpretable, and standardise them across all AI models.

Examples of drug warning labels that are designed for noticeability and interpretability
As a last resort, if the safety issue is serious enough, and it is safe to do so, a regulator should have the power to recall AI models from the market.
3. Reporting safety issues must be easy and rewarded
The MedWatch programme made reporting safety issues much easier – you could post, phone or fax in your report. With the advent of the internet, it now just takes a few clicks. These user-friendly systems are correlated with a dramatic increase in the number of reports filed over the last thirty years.
At the moment, that’s quite difficult for AI. While tools such as the AI Incident Database offer a relatively straightforward reporting process, it is more onerous than necessary for reporting on a digital interaction: users are required to go to a separate website to file the problem, and manually input many data fields. What’s more, interactions on ChatGPT, for example, take place in a closed space that only the user can access, and interactions are long and not easily shared or screenshotted.
This is why services like ShareGPT – a Chrome plugin that allows you to share your interaction with ChatGPT to a public database with a single click – have been so popular. Users of ShareGPT have already shared 350,000 conversations in a few months.
But it is not enough to be easy; reporting must also be rewarded. Without a reward, people won’t do it.
One obvious way to reward is to pay. This has a long tradition in cybersecurity, known as bug bounties. The Algorithmic Justice League has specifically proposed using bug bounties to look for AI safety issues, and this was trialled by Twitter in 2021, when it offered to pay users if they could find safety issues with its cropping algorithm (they found many).
However, payments are not the only – and perhaps not the best – way to reward reporters. The MedWatch and Yellow Card programmes do not pay doctors to report safety issues. They instead depend on (and invest time and money to cultivate) a sense of professional duty to report. This type of incentive has been proven in other contexts — such as giving blood — to be more effective than payment. What’s more, bug bounties can amount to poorly paid gig work with no employment protections, and provide incentives to maximise reports that could corrupt the data.
Another incentive to consider is social rewards. This is what current beta tests rely on: the prestige of exposing a problem to a networked audience on social media. One mechanism to consider would be social rewards such as upvotes, bookmarks and comments, some of which are provided by ShareGPT.
How to make reporting easy, and how best to reward it, are two design challenges that should be urgent areas of research.
4. Communities of reporters must be engaged and educated
Just as the FDA has found that engagement and education with doctors has driven up report rates (in some cases by 17 times), so too should AI Phase 4 trials educate its key stakeholders, such as programmers, to know what to look for and report.
The identification of safety issues been found to focus on certain types of harms, such as security (e.g. jail breaking) and discrimination (e.g. racist bias). Both of these are critical safety issues, and if more people were educated in what to look for, more of those safety issues would be found.

A graph of the most common tests of AI models by crowdsourced red teamers, showing they tend to focus more on some harms than others, which may also be the case for Phase 4 trials without adequate education (source: https://arxiv.org/pdf/2209.07858.pdf)
We might also consider how to train reporters to look for other kinds of safety issues. For example, what kinds of behaviours do reporters need to be aware of when identifying privacy issues (which have been found to be neglected in crowdsourced red teams), or misalignment?
Educating and engaging a community of reporters — whether that’s programmers or end users — will take time, research, and investment. Just because reporters are not paid, this does not mean that Phase 4 trials should be considered a ‘free’ solution. It’s not, and will need proper funding.
5. Reports should be used to detect canaries
It might seem like extreme risks are precisely what we shouldn’t be waiting until deployment to find. The catastrophic harm would already be done.
An alternative view on this problem is the idea of canaries, which Oren Etzioni defines as “an early warning of AI breakthroughs on the horizon”. Canaries are important both for both understanding how AI is evolving through its usage, and what important political debates may need to get started given upcoming capabilities.
This is something that safety reports are well suited to supporting. They are not complete data or controlled tests, and they will possess biases based on the types of people that report and the types of issues they report on.
As a result, Phase 4 trials are best suited to generating, rather than testing, hypotheses.
In AI safety, those hypotheses could – and I think should – support the identification of canaries, helping AI safety researchers and policymakers grapple with emerging issues that only come into view with deployed systems.
MedWatch for AI
I think it’s important for the AI safety field to raise awareness of the inadequacy of existing post-deployment reporting mechanisms, and regard this as a relatively under-developed area of AI safety.
And, given the technical and design challenges facing a ‘MedWatch for AI’ programme (how do you actually get high quality reports of AI safety issues on a massive scale?), a challenge fund could spur investment where the market is currently failing, as could government-run initiative.
But most of all, by looking to industries with far more mature safety standards — such as the pharmaceutical industry — we’ll gather important lessons for how to make AI safe.
Thanks to Professor Noortje Marres who helped me develop these ideas before I drafted this post.
UPDATE (16/11/23): I added the ‘five principles for AI phase 4 trials’ to the introduction for those unable to read the full post.